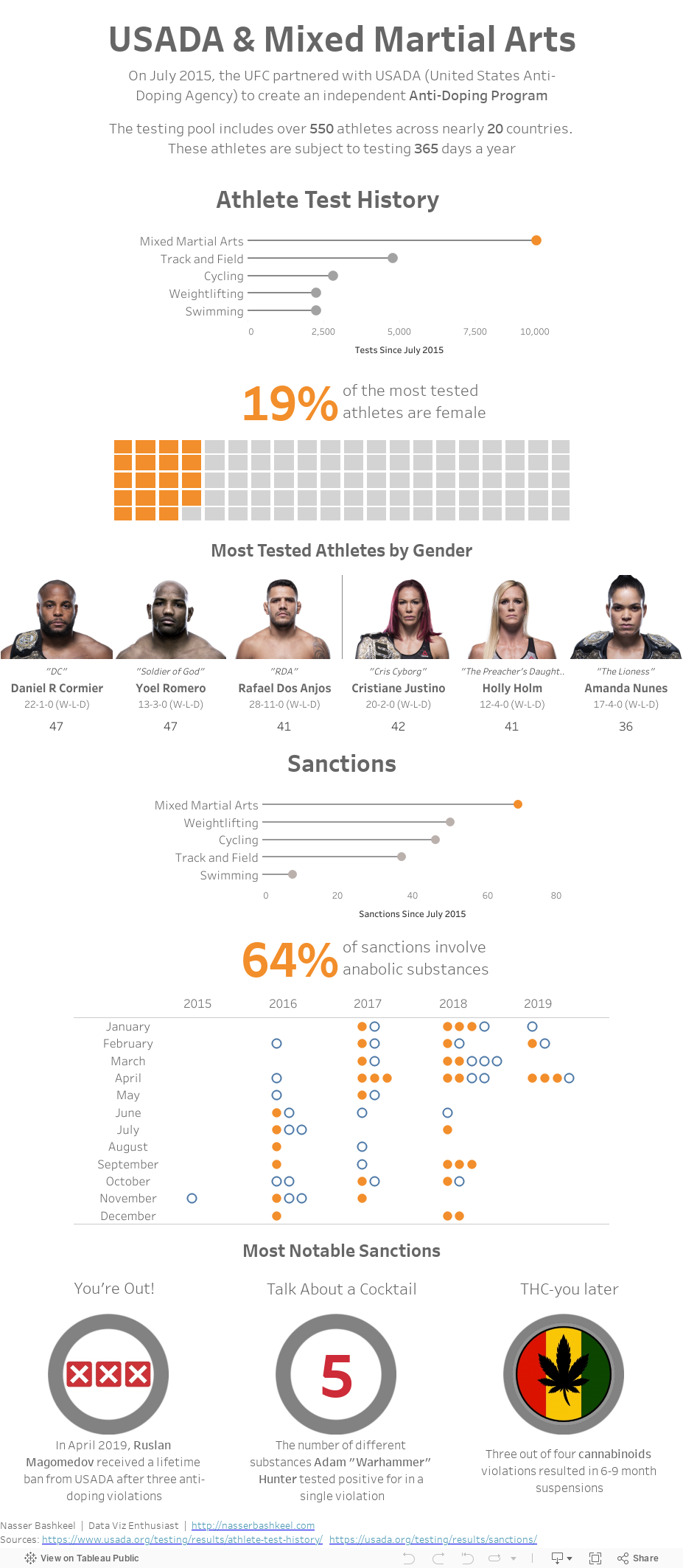
Web Scraping & Data Wrangling Code
Required Libraries
library(RSelenium)
library(rvest)
library(XML)
library(tidyverse)
Web Scraping
rD <- rsDriver(browser = "chrome", chromever="73.0.3683.68")
remDr <- rD[['client']]
url <- "https://www.usada.org/testing/results/athlete-test-history/"
remDr$navigate(url)
years_dropdown <- remDr$findElement(using='xpath', '//*[(@id = "years")]')
years_text <- years_dropdown$getElementAttribute("outerHTML")[[1]]
years_xml <- htmlTreeParse(years_text, useInternalNodes = TRUE)
years_numbers <- unlist(years_xml["//option", fun = function(x) xmlGetAttr(x, "value")][-1])
Q_dropdown <- remDr$findElement(using='xpath', '//*[(@id = "quarters")]')
Q_text <- Q_dropdown$getElementAttribute("outerHTML")[[1]]
Q_xml <- htmlTreeParse(Q_text, useInternalNodes = TRUE)
Q_numbers <- unlist(Q_xml["//option", fun = function(x) xmlGetAttr(x, "value")][-1])
Scrape USADA testing data & write to csv
complete_df <- NULL
for (year in years_numbers) {
for (quarter in Q_numbers) {
select_year <- remDr$findElement(using='xpath', paste0("//*[(@id = 'years')]/option[@value = '", year, "']"))$clickElement()
select_quarter <- remDr$findElement(using='xpath', paste0("//*[(@id = 'quarters')]/option[@value = '", quarter, "']"))$clickElement()
search_table <- remDr$findElement(using='xpath', '//*[contains(concat( " ", @class, " " ), concat( " ", "inputButton", " " ))]')$clickElement()
doc <- htmlParse(remDr$getPageSource()[[1]])
df <- readHTMLTable(doc)[[2]] %>%
select_if(function(x) !(all(is.na(x)) | all(x==""))) %>%
setNames(lapply(slice(.,1), as.character)) %>%
slice(2:n()) %>%
add_column(Year = rep(year, nrow(.)), Quarter = rep(toupper(quarter), nrow(.)))
complete_df <- rbind(complete_df, df)
}
}
rD[["server"]]$stop()
write.csv(complete_df, "Full Testing Data.csv", row.names = FALSE)
Scrape USADA Sanctions
url = "https://www.usada.org/testing/results/sanctions/"
rD <- rsDriver(browser = "chrome", chromever="73.0.3683.68")
remDr <- rD[['client']]
remDr$navigate(url)
doc <- htmlParse(remDr$getPageSource()[[1]])
df <- readHTMLTable(doc)[[2]]
write.csv(df, "USADA Violations.csv", row.names=FALSE)
Data Preparation
df <- read.csv("Full Testing Data.csv")
violations <- read.csv("USADA Violations.csv", na.strings = c("", "NA"))
violations$Athlete <- sub("(\\w+),\\s(\\w+)","\\2 \\1", violations$Athlete)
gender <- read.csv("Fighter Gender.csv")
Waffle Plot - Top 100 Most Tested Fighters
top_100 <- df %>% filter(Sport == "Mixed Martial Arts" ) %>% select(-c(Sport)) %>%
group_by(Athlete.Name, Year) %>% summarise(Test.Count = sum(Test.Count)) %>%
spread(key = Year, value = Test.Count, fill = 0) %>%
mutate(Total = sum(`2015`, `2016`, `2017`, `2018`, `2019`)) %>%
merge(., gender, by='Athlete.Name') %>%
arrange(desc(Total)) %>% slice(1:100) %>%
mutate(Sex = factor(Sex, levels=c("F","M"))) %>%
arrange(-desc(Sex), desc(Total))
tab_waffle <- top_100 %>%
waffle_iron(aes_d(group=Sex), rows=5) %>%
mutate(group = as.factor(group))
tab_waffle <- cbind(top_100, tab_waffle)
#write.csv(tab_waffle, "tab_waffle.csv", row.names = F)
Top 3 Tested Men & Women
top_6 <- df %>% filter(Sport == "Mixed Martial Arts") %>% select(-c(Sport)) %>%
group_by(Athlete.Name, Year) %>% summarise(Test.Count = sum(Test.Count)) %>%
spread(key = Year, value = Test.Count, fill = 0) %>%
add_column(Total = rowSums(.[-1])) %>%
merge(., gender, by='Athlete.Name') %>%
arrange(desc(Total)) %>% group_by(Sex) %>%
top_n(n=3, wt=Total) %>% .[1:6,]
#write.csv(top_6, "Top Tested Athletes.csv", row.names = F)
Data Required for Sanctions Calendar
tab_calendar <- violations %>% filter(Sport == "Mixed Martial Arts") %>%
mutate(Sanction.Announced = as.Date(Sanction.Announced, format="%m/%d/%Y")) %>% na.omit() %>%
mutate(Year = format(Sanction.Announced, "%Y"),
Month = factor(format(Sanction.Announced, "%B")),
Cell = format(Sanction.Announced, "%b/%Y")) %>%
group_by(Cell, .drop=FALSE)
#write.csv(tab_calendar, "Tab_Calendar.csv", row.names = F)